
Disclosure: Some links in this article may be affiliate links. This means we may earn a commission if you click and make a purchase, at no additional cost to you. Read full disclosure here.
You have more control over search engines than you realize.
For example, you can decide who is allowed to crawl and index your website – right down to individual subpages. The robots.txt file will help you with this. It is a simple text file that is located in the root directory of your website.
It communicates to the crawl bots of a search engine which websites should be crawled and which should be left out.
Even if the file is not omnipotent, it is still a powerful tool and allows you to present yourself to Google the way you want it to be. Search engines are tough critics, which is why it’s important to leave a lasting good impression.
The robots.txt file, if used correctly, can increase the crawl frequency of your website, which can lead to faster results for your SEO efforts.
So how do you create such a robots.txt file? How is it used? What should be avoided? You can find answers to all of these questions in this post!
What is the robots.txt file anyway?
When the Internet was still in its infancy, but its great potential was already evident, developers created a way to crawl and index new Internet pages.
They named these little scripts “Bots” and “Spiders”. In the process, these bots often came to websites that were not intended for crawling and indexing, because they are only sample pages or have just been maintained.
The creator of the world’s first search engine, Aliweb, created a kind of roadmap that every crawling bot should follow.
This roadmap was finalized in 1994 by a collective of experienced web developers as the “Robots Exclusion Protocol ” .
A robots.txt file is the execution of this protocol. The protocol sets out the guidelines that every authentic bot must follow, including Google bots. Some illegitimate bots, such as By definition, malware, spyware and the like operate outside of these rules.
You can take a look behind the scenes of any website by entering any URL and adding /robots.txt to the end.
For example, here’s the robot.txt version of Nikola Roza:
 robot.txt example
robot.txt example
As you can see, there is no need to have an egg-laying woolen milk sow as a file as POD Digital is a relatively small website.
Where to find the robots.txt file
Your robots.txt file is saved in the root directory of your website. To find them, open your FTP cPanel. There you will find the file in the “public_html” directory of your website.
 FTP file manager
FTP file manager
The files do not contain complex media, just a simple text format. Therefore, they are only a few hundred bytes, if any.
Once you’ve opened the file with your text editor, you’ll be greeted with a sight like this:
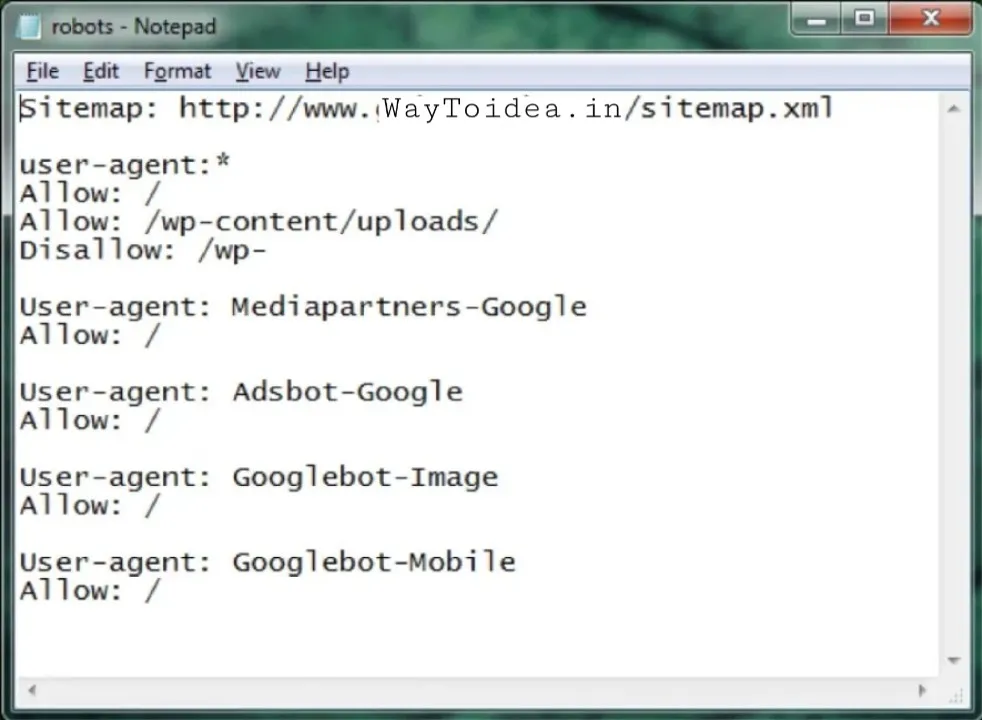 Robot.txt text on notepad
Robot.txt text on notepad
If you can’t find a robots.txt file because it doesn’t exist, you should create one yourself.
How to create a robots.txt file?
There are two simple ways to create a perfect robots.txt file in WordPress. You can choose the method that works best for you.
Method 1: Editing Robots.txt File Using Yoast SEO
If you are using the Yoast SEO plugin , then it already comes with a robots.txt file generator. You can use it to create and edit a robots.txt file directly from your WordPress admin area. Simply go to SEO » Tools page in your WordPress admin and click on the File Editor link.

On the next page, Yoast SEO page will show your existing robots.txt file. If you don’t have a robots.txt file, then Yoast SEO will generate a perfect robots.txt file for you.

By default, Yoast SEO’s robots.txt file generator will add the following rules to your robots.txt file:
User-agent: *
Disallow: /
It is important that you delete this text because it blocks all search engines from crawling your website.
After deleting the default text, you can go ahead and add your own robots.txt rules.
We recommend using the ideal robots.txt format we shared above. Once you’re done, don’t forget to click on the ‘Save robots.txt file’ button to store your changes.
Method 2. Edit Robots.txt file Manually Using FTP
All you need is a simple text editor like Notepad. Open a sheet and save the blank page as “robots.txt”.
Now log into your cPanel and look for the “public_html” folder to access the root directory of the website. Once this is open, drag your file into it.
Finally, you need to make sure that you have correctly set the permissions on the file.
Ideally, only you as the owner should be allowed to read, write and edit the file. Other users should not be allowed to do this.
Therefore, the file should have an access code of “0644”.
If this is not already the case, you should change this. To do this, click on the file and select “Authorization”.
Voila! Your robots.txt file is complete!
- Save Money and Time with Smart Waste Management Solutions
- The Advantages of Small Business Local Search Engine Optimization Services
- How Visual Testing Helps Avoid Regressions After Software Updates: Securing Seamless Performance
- The History of Glass: From Antiquity to Modern Times
- Thriving in Property Management: A Roadmap to Success
The robots.txt syntax
A robots.txt file consists of several command sections in code form, each of which begins with a specific user agent. The user agent is the name of the specific crawl bot that the code will interact with.
There are two options:
- You can use a wildcard to address all search engines at the same time.
- You can address certain search engines individually.
When a bot is used to search a web page, it will automatically read the command sections that address it.
Here is an example:
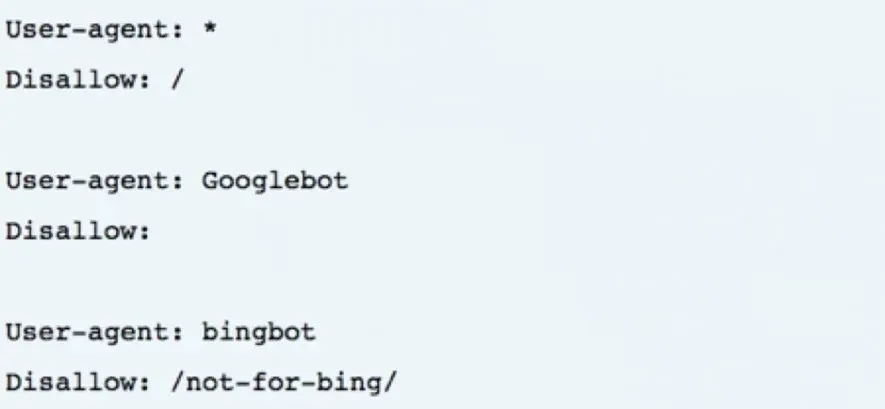 Robot.txt syntax
Robot.txt syntax
User agent command
The first lines in each block are dedicated to the user agent who addresses the respective bot of the search engine. The user agent contains the name of the bot:
 User agent command
User agent command
So if you want to give commands to the google bot use:
User agent: Googlebot
Search engines always try to find specific commands that relate to them.
Even if, for example, you have two commands in the file: one for the Google Bot and one for the Bing Bot.
The bingbot that encounters the user agent “Bingbot” will execute this command. The bot “Googlebot Video”, however, will skip this command and look for a more specific instruction.
Most search engines have a few different bots, here is a list of the most common ones .
Host command
Currently, the host command is only supported by Yandex , even though Google is rumored to be. This command allows a user to decide whether the www . should be displayed before a URL with this block:
Host: poddigital.de
Since only Yandex certainly supports this command, it is not advisable to use it. Instead, you should use a 301 redirect for forwarding.
Disallow command
We’ll look at this command in more detail later.
The second line of a block in the file contains the Disallow commands. You can use them to determine which areas of the website the bot should not be allowed to access. An empty disallow block means that there are no restrictions.
Sitemap commands (XML sitemaps)
You use the sitemap commands to tell search engines where to find your XML sitemap .
Still, it is probably best to submit the sitemap to Webmaster Tools in any search engine. They contain a lot of valuable and important information about your website.
If you don’t have time to do this, you can use the sitemap command.
Crawl delay command
Yahoo, Bing, and Yandex tend to crawl prematurely, but you can control behavior with a Crawl Delay command.
By adding this line to your block:
Crawl delay: 10
Tell the search engine to wait 10 seconds before crawling the web page or wait 10 seconds before revisiting the page after crawling. In the end, it comes down to the same thing, but the individual search engines act slightly differently.
Why you should use the robots.txt file?
You now have a basic understanding of the robots.txt file and some commands and their uses. You can create your own file. However, the next step depends on the type of content on your website.
Overall, the robots.txt file is not critical to the success of your website. In fact, your website can thrive and get high rankings even without this file.
However, there are a few advantages to using it that you should know before you forego the file :
- You can protect private directories from bots: by entering the appropriate command in the file, you make it more difficult for search engines to index sensitive directories.
- You control your resources: every time a bot crawls your website, your hosting resources are used. With huge websites with a lot of content, such as e-commerce sites with thousands of subpages, crawling can quickly put a strain on your resources. With the robots.txt file, you can make certain subpages or elements difficult to access for search engines and thus save your valuable resources for the visitor.
- You communicate the location of your sitemap: This point is important because the crawling bots should know where your sitemap is at all times so that they can read it quickly.
- You prevent duplicate content: If you include the instruction in the file, you prevent the subpages with duplicate content from being indexed.
Of course, you want search engines to have the best possible access to your most important subpages. By politely blocking off certain pages, you can control which pages are shown to searchers and which are not (just make sure you never completely stop search engines from seeing certain sub- pages ).
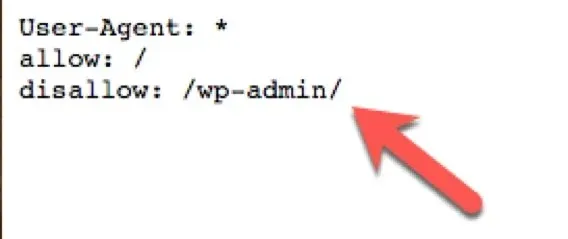 User agent disallow
User agent disallow
For example, if we take a look at the my website’s Robots File, we see that the following URL
- WayToidea.in/wp-admin – was given a disallow command.
Since this page was created just for us so that we can log into the control panel, it makes no sense to allow the bots to crawl it.
Noindex
In July 2019, Google announced that it would no longer support the noindex command, as well as many other unofficial rules that many webmasters have relied on.
So many of us have looked for alternative methods that can achieve the same result. Below are some of these options that can help you achieve the same effect.
- Noindex Tag / Noindex HTTP Response Header : This tag can be implemented in two ways: Firstly, as an HTTP response header with an X-Robots tag or by creating a
<meta>tag within the<head>section.
Your <meta> tag should look like the following example: <meta name = “robots” content = “noindex”>
TIP: Remember that if this page was blocked by the robots.txt file, the crawler will never see your noindex tag, and there is still a chance that this page will be included in the SERPs.
- Password protection: Google states that most of the sub-pages that hide behind a login will be removed from the Google index. The only exception is subscription or paywall content that you have appropriately tagged with schema markup .
- 404 & 410 HTTP status code: 404 & 410 status codes represent the pages that no longer exist. As soon as a page with a 404/410 status has been crawled and completely processed, it is automatically removed from the Google index.
You should crawl your page regularly to rule out 404 & 410 errors. If there are error codes, you should set up a 301 redirect to send the traffic to an existing subpage.
- Disallow command in the robots.txt: By adding a page-specific Disallow command to your robots.txt file, you prevent the search engine from crawling this subpage. In most cases, this will not index the page or its content. However, you should be aware that the search engines are still able to index the subpage based on links from other pages or other information.
- Search Console URL Removal Tool : This alternative does not completely solve the indexing problem because the Search Console tool only removes the URL from the SERPs for some time.
However, this could give you enough time to prepare more crawler rules and tags so that the pages could be completely removed from the SERPs.
You can find the Remove URL Tool on the left side of the main navigation in the Google Search Console.
 Google search console removal tool
Google search console removal tool
Noindex vs. Disallow
Many of you are probably wondering whether it is better to use the noindex tag or the disallow rule in your robots.txt file. We have already covered in the previous part why the noindex rule is no longer supported in robots.txt and various alternatives.
If you want to make sure that any of your pages are not being indexed by search engines, you should definitely take a look at the noindex meta tag. It allows the bots to access the page, but the tag tells that this page should not be indexed and should not appear in the SERPs.
The Disallow command might not be as effective as the noindex tag. Of course, by using the command in robots.txt you are preventing the bots from crawling your page, but if the mentioned page is connected to other pages by internal and external links, the bots could still index that page based on information provided by other sites.
You should remember that if you lock the page with a disallow rule and add the noindex tag, the robots will never see your noindex tag, which in turn can cause the page to appear in the SERPs.
The use of regular expressions and wildcards
So we now know exactly what the robots.txt file is and how it should be used. Now, on a large ecommerce site, you might want to exclude all URLs from the index that contain a question mark.
We would therefore like to introduce you to the principle of wildcards that can be integrated into robots.txt. There are currently two variants of the wildcards that you can use.
-
- Placeholder – here the character * can be replaced with any special character or character string according to your wishes. These type of placeholders are a great solution for your URLs that are of a similar format. For example, you can undercut the crawling of all filter pages that contain a question mark (?) In the URL.

- $ Placeholder – this replaces the $ symbol with the end of the URL to be excluded. For example, if you want to prevent all PDF files from being indexed, you should implement a command like the one below:

Let’s quickly break down the example above. Your robots.txt allows all user agent bots to crawl your website, but it prohibits access to any page that contains a .pdf extension.
Mistakes to Avoid
You are now familiar with several uses of your robots.txt file. We’re going to dig a little deeper into each point in this section and explain how each one can become an SEO disaster if not used properly.
Don’t block good content
You should present your good content to the public and under no circumstances block it with the robots.txt file or the noindex tag. In the past, we have encountered several of these mistakes that have harmed the effectiveness of SEO campaigns. You should carefully examine your pages for any noindex tags and disallow commands.
Excessive use of the crawl delay
We already explained how the Crawl Delay command can be used and what it does. However, you shouldn’t use it too often as it could limit the SEO potential of the pages in question. For some websites it may be the perfect solution. But especially with larger pages, the command could backfire and hinder your rankings and thus solid traffic.
Consideration of upper and lower case
The robots.txt file is case-sensitive. This should be taken into account when creating the file. So rename the file “robots.txt” in lower case for it to work.
Using Robots.txt to prevent content from being indexed
We have already touched on this part above. Locking a subpage about the file is the best way to prevent the bot from crawling.
This can, but does not have to work:
- If the subpage has already been linked from an external source, the bots will get to the subpage via this source, crawl it and still index it.
- Illegitimate bots can always crawl and index the subpage.
Use of Robots.txt to shield private content
Some content that is not intended for the general public, such as PDFs or thank you pages, can be indexed even if you want to prevent the bot from doing so. An effective way to enforce the disallow command is to place private content behind a login.
Of course, this involves another step, but your content is protected.
Avoid harmful duplicate content with Robots.txt
Sometimes duplicate content cannot be avoided, as with printer-friendly subpages.
Still, Google and other search engines are advanced enough to know when you want to hide something. In fact, you only attract more attention to yourself and your duplicate content.
Google now recognizes the difference between natural duplicate content, such as printer-friendly subpages, and the attempt to fool the algorithm.
 duplicate content algorithm
duplicate content algorithm
There’s a chance he’ll be discovered anyway.
There are three methods you should use to handle this type of content:
- Rewrite the content: Creating exciting and useful content will cause the search engine to consider your website trustworthy, which can lead to better rankings in the long term. You should take this advice to heart, especially when it comes to a copy-and-paste task.
- Set up a 301 redirect: 301 redirects inform search engines that a subpage has been transferred to another location. Put a 301 on a page with duplicate content and redirect visitors to the original page of content.
- Rel = “canonical: This tag informs Google of the original location of duplicated content. This is particularly relevant for an e-commerce website, as the CMS very often displays identical content in two versions.
The moment of truth: test your Robots.txt file
Now is the time to test your file to see if everything works the way you want it.
Google’s Webmaster Tools have a test function for the robots.txt, but this is currently only available in the old version of the Google search console (Google is currently expanding the functions of the search console, so that we may have a test function for the Robots.txt in the future in the current version).
First you will have to visit the Google Support page, where you will get an overview of the functions of the Robots.txt test function. You will also find the test tool there:
 Google help center
Google help center
First select the property you are working on – for example, your company website from the drop-down list.
 Robot.txt tester Google
Robot.txt tester Google
Remove whatever is currently in the box, replace it with your new robots.txt file, and click “Test”.
If the button “Test” switches to “Allowed”, your robots.txt file is fully functional. Correct creation of this file will allow you to improve your SEO and user experience.
By communicating to the bots how to properly crawl your website, they are able to structure their content and present it in the form you want.
If you have any question or suggestion then feel free to comment us.

Founder @ WayToIdea
Founder @ WayToIdea
Vishal Meena is an SEO specialist and the founder of WayToIdea. Since starting his journey in 2019, he has helped 96+ clients across the US, UK, and India grow through technical SEO and data-driven strategies. With a background in Mathematics and digital marketing form Harvard Business School, he approaches search like a system to be analyzed, optimized, and scaled.
Loading comments...






